Несмотря на то, что многие из нас годами работают в сфере сопровождения информационных систем и сервисов, в профессиональной среде все еще сохраняется некоторая путаница в использовании базовой терминологии. Разделение понятий «авария» и «инцидент» часто вызывает трудности даже у профильных специалистов, хотя точное понимание разницы между ними критически важно для эффективной работы ИТ-служб и бизнеса в целом.
Представляем небольшой материал, нацеленный на ликвидацию пробела в терминах и прояснение их роли в контексте систем мониторинга и ITSM (IT Service Management, управление ИТ-сервисами).
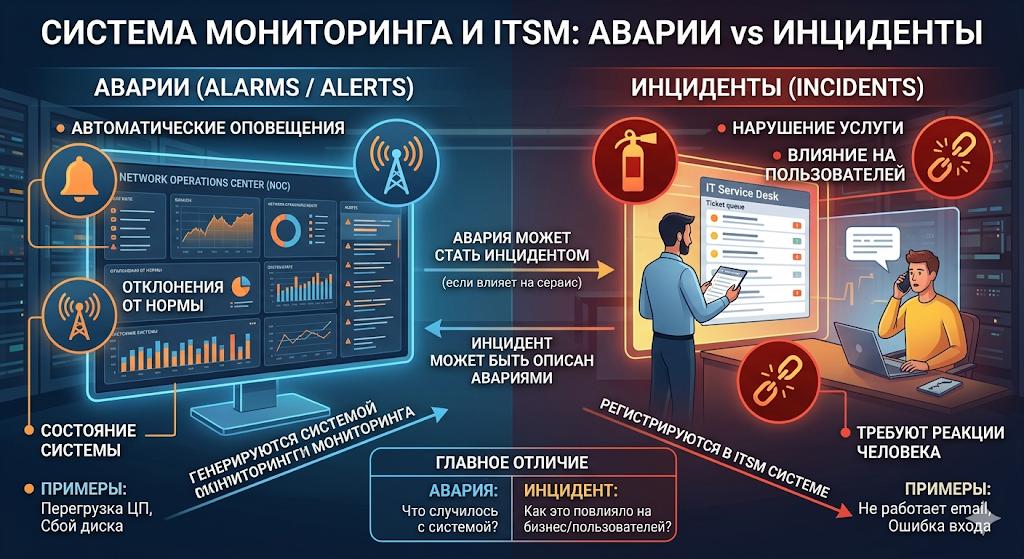
В зрелой ИТ-организации термины «event», «alarm»/«alert» и «incident» не следует использовать как взаимозаменяемые. Если смешивать эти понятия, мониторинг быстро превращается в шум, а Service Desk – в склад технических срабатываний без бизнес-контекста.
Важность вопроса
Мониторинг фиксирует состояние наблюдаемых систем, а ITSM управляет влиянием обнаруживаемых событий на услугу и пользователя. В терминах стандарта ITIL (Information Technology Infrastructure Library) инцидент – это незапланированное прерывание или снижение качества сервиса, тогда как тревога (или alert) – это сигнал мониторинга, указывающий на возможную проблему, но еще не обязательно подтверждающий инцидент.
Термины
В практической архитектуре удобно разделять уровень наблюдения и уровень обслуживания:
| Понятие | Смысл | Где живет |
| Событие Event | Сырой факт: метрика, статус, изменение состояния | Система мониторинга |
| Авария Alarm / Alert | Нормализованный сигнал о потенциальной аномалии | Мониторинг, AIOps, NMS |
| Инцидент Incident | Подтвержденное нарушение сервиса, требующее восстановления | ITSM / Service Desk |
Такое разделение соответствует распространенной практике – события собираются постоянно, аварии возникают по правилам и порогам, а инциденты создаются только после проверки их влияния на сервис.
Аварии и инциденты в логике ITIL
В концепции ITIL авария (или алерт) не тождественен инциденту. Авария сообщает технической команде – «проверьте», а инцидент говорит бизнесу и эксплуатации – «сервис уже нарушен или скоро будет нарушен, требуется восстановление».
По этой причине алерт должен проходить этап валидации, корреляции и приоритизации. В том случае, если автоматически превращать каждое срабатывание в инцидент, система утонет в дублях, а реальные аварии потеряются среди технического шума.
В русле eTOM
В модели eTOM (enhanced Telecom Operations Map) обсуждаемая логика хорошо укладывается в цепочку операционного управления услугой – мониторинг, обнаружение, оценка влияния, эскалация и восстановление. Иначе говоря, авария – это входной сигнал для операционных процессов (operations), а инцидент – уже управляемая сущность процесса Fulfillment/Assurance (выполнение/обеспечение), которая требует назначения, SLA-контроля и восстановления сервиса.
Для телеком- и крупных инфраструктурных сред это особенно важно: одна авария может быть следствием деградации узла, а может – лишь симптомом. eTOM-подход помогает не спорить о терминах, а выстраивать цепочку от наблюдения к управлению услугой и клиентским воздействием.
Согласованность с COBIT
Как уже обсуждалось, в терминологии ITIL авария – это сигнал о возможной проблеме, а инцидент – подтвержденное нарушение сервиса. Фреймворк для управления и контроля ИТ-процессов COBIT (Control Objectives for Information and Related Technologies) отменяет такую логику, добавляя к ней управленческую дисциплину – расследование, диагностику, назначение ответственности и контроль эффективности процесса.
Практическая модель
Хорошая практико-ориентированная схема обычно выглядит так:
- Система мониторинга получает сырой факт («raw event») или метрику («metric»).
- Правило классификации и корреляции превращает его в аварию («alarm» или «alert»).
- Ранжирование и обогащение добавляют контекст: сервис, конфигурационная единица, владелец, SLA, клиент.
- В случае, если подтверждено влияние на сервис, создается инцидент.
- Инцидент дальше живет по правилам ITIL: приоритет, эскалация, восстановление, закрытие.
Такой путь позволяет отделить «шум датчика» от «события, которое реально мешает бизнесу».
Что показывают производители
У крупных ИТ-платформ используется, в целом, сходная логика. SolarWinds явно поддерживает сценарии, где «alert» инициирует «incident» в интегрированной ITSM-системе, а двусторонняя связь позволяет синхронизировать статусы и изменения.
Похожие подходы применяются и у IBM, Micro Focus, Datadog: мониторинг, APM и наблюдаемость (observability) не подменяют ITSM, а передают в него только то, что прошло проверку на значимость для сервиса. Это и есть «взрослая» модель – мониторинг обнаруживает, ITSM управляет, а не наоборот.
Типовые ошибки
Чаще всего организации ошибаются в трех местах:
- создают инцидент на каждое алерт-срабатывание
- не связывают аварию с бизнес-сервисом и CMDB (Configuration Management Database, база данных управления конфигурациями)
- не разделяют техническую аварию, подтвержденный инцидент и последующее управление проблемами (problem management)
В результате теряется приоритизация, нарушается SLA-логика и размывается ответственность между оперативным центром управления инфраструктурой (ЦУС или Network Operations Center, NOC), Service Desk и владельцами сервисов.
Финальная формулировка
В итоге, если сформулировать совсем коротко, то:
- авария отвечает на вопрос – «что-то произошло?»
- инцидент отвечает на вопрос – «нарушена ли услуга и что делать для восстановления?»
- ITIL и eTOM помогают выстроить между ними управляемую цепочку так, чтобы мониторинг не становился хаосом, а эксплуатация – реакцией на реальную бизнес-проблему